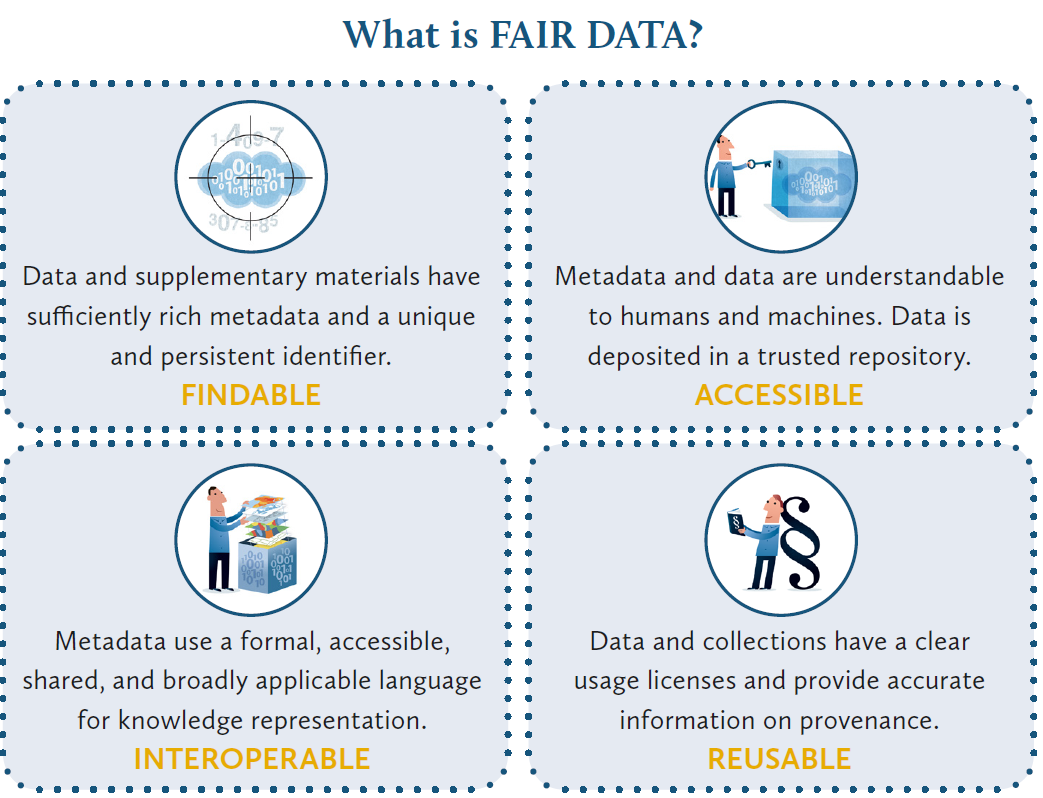
Vor dem Hintergrund der FAIR-Prinzipien stellt sich die Frage nach der Bedeutung von Metadaten eigentlich gar nicht, leisten sie doch zu zwei der vier in dem Akronym einprägsam zusammengefassten Kategorien einen wesentlichen Beitrag, indem sie eine Forschungsdatenpublikation besser auffindbar (findable) und die Zusammenführung von Datensatznachweisen (interoperable) in institutionen-, länder- oder disziplinübergreifenden Katalogen möglich machen. Soweit die Theorie. Doch wie verhält es sich in der Praxis? Erhalten Metadaten immer die Aufmerksamkeit, die sie verdient haben, oder wirken sie im Schatten der Forschungsleistung und der dafür erforderlichen zeitintensiven Datenerhebung, -aufbereitung und -auswertung eher wie ein notwendiges Übel, eine lästige Pflicht, die es auf dem Weg zur Datenpublikation eben schnell zu erfüllen gilt, um Forschungsförderer und Infrastruktureinrichtungen zufriedenzustellen? Bieten die Systeme und Standards überhaupt die Möglichkeit, Forschungsdaten adäquat – beispielsweise unter Rückgriff auf Normdaten oder mehrsprachig – zu beschreiben? Eine ehrliche Beantwortung dieser Fragen zeigt auf, wo Verbesserungspotenzial besteht. Ziel dieses Beitrags ist es, ebenso ein Bewusstsein für die Herausforderungen bei der Erschließung von Forschungsdaten zu wecken wie für den hilfreichen Nutzen, der sich aus dem Bemühen um qualitativ hochwertige Metadaten ergibt. Mit dem Begriff „Metadaten“ sind in diesem Beitrag die bei der Publikation von Forschungsdaten hinzugefügten, das Forschungsprojekt sowie die hinterlegten Datensätze beschreibenden Informationen gemeint. Im Rahmen der Aufbereitung der Rohdaten zur Beantwortung der Forschungsfrage ergänzte strukturierende und beschreibende Elemente wie Annotationen oder Markup-Elemente (bspw. der TEI-Header, XML-Tags usw.) werden hingegen als Bestandteil der von den Metadaten unterschiedenen Forschungsdaten betrachtet.
„Qualitative Metadaten – Hilfe und Herausforderung zugleich“ weiterlesen