Julia Röttgermann und Christof Schöch
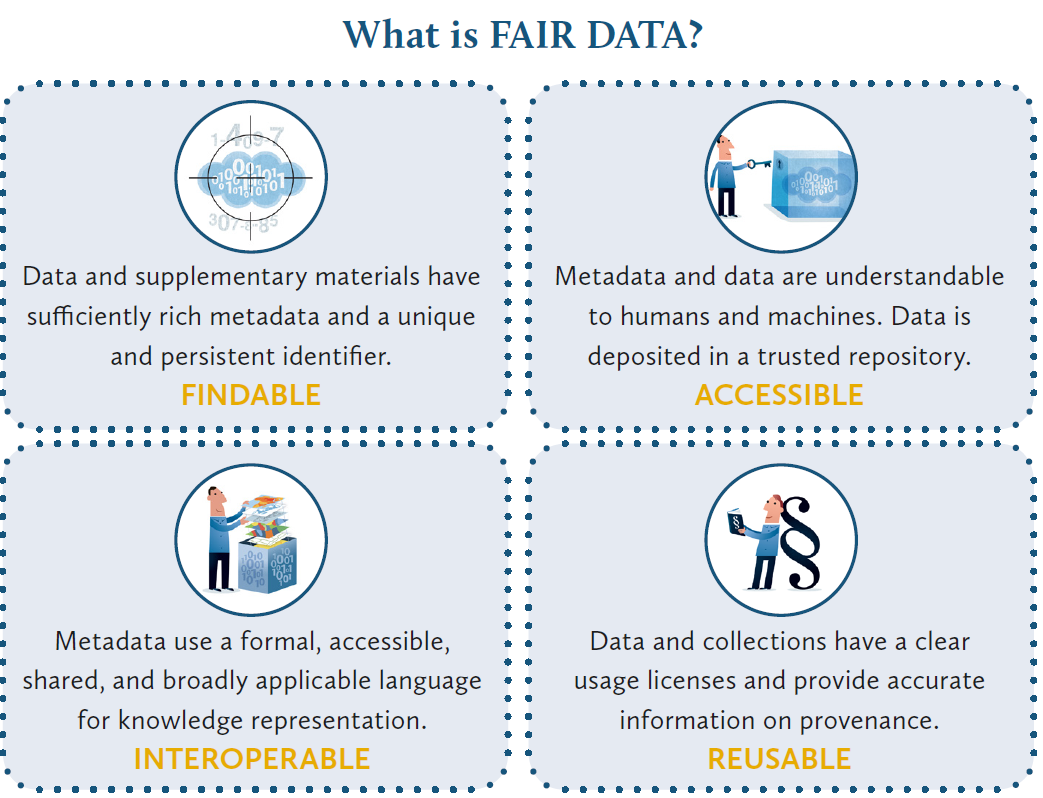
Gemäß der Fair Data Principles sollen Forschungsdaten “Findable, Accessible, Interoperable, and Re-usable“, also auffindbar, zugänglich, interoperabel und nachnutzbar sein. In der vorliegenden Blogserie zu FAIR-Prinzipien im Kontext romanistischer Projekte wurden bereits die Bedeutung von Repositorien und FAIR data im Kontext der Lexikographie diskutiert.
Im Projekt “Mining and Modeling Text” (2019–2022) des Trier Center for Digital Humanities ist ein Team aus der Computerlinguistik, der Romanistik, der Informatik und der Rechtswissenschaft dabei, ein mehrgliedriges Informationsangebot aufzubauen. Die Informationen speisen sich aus drei Quellen: Primärtexte (französische Romane der Zeit 1750-1800), Sekundärliteratur (relevante literaturhistorische Werke) und relevante bibliographische Daten.
Geleitet von der Idee von Linked Open Data werden die Romane in TEI-konformes XML gewandelt und mit Normdaten wie Wikidata verknüpft. Die Vision des Forschungsprojekts ist es, literaturhistorisch relevante Informationen maschinell zu extrahieren und so in Form von einfachen Aussagen zu modellieren, dass sie im Sinne des Semantic Web abfragbar (via SPARQL) zur Verfügung stehen.
Doch sind die bisher erhobenen Forschungsdaten den FAIR-Prinzipien entsprechend gut zugänglich, umfänglich erläutert, mit entsprechenden Lizenzen versehen und stehen sie nachnutzbar aufbereitet für die Forschungscommunity zur Verfügung?
Bei der Aufbereitung der französischen Romane als TEI-Dokumente leistet das Projekt MiMoText echte Pionierarbeit: Selbst hochkanonische Texte von Denis Diderot, dem Marquis de Sade oder Voltaire standen bisher nicht als TEI-konformes XML zur Verfügung.
Zum kollaborativen Aufbau des Romankorpus nutzt das Projektteam GitHub, das entsprechende Repository steht seit Projektbeginn für die Öffentlichkeit online verfügbar und dokumentiert so den Projektfortschritt. Die entsprechenden Forschungsdaten (Romane als plain text und in XML, aber auch Python-Skripte zur Formatkonversion der Dateien) stehen von Anbeginn frei und mit einer Public Domain-Lizenz versehen zur Verfügung. Im teiHeader der Dateien sind Informationen wie firstEdition, printSource und digitalSource verzeichnet. Das Kriterium der Reusability (klare Nutzungslizenz, akkurate Informationen über die Provenienz der Daten) ist somit erfüllt.
Die auf GitHub publizierten XML-Dateien sind mit Metadaten angereichert, die in Form einer Google-Tabelle gepflegt und in regelmäßigen Abständen als csv im GitHub-Repository veröffentlicht werden. Zu jedem Roman werden Metadaten wie Namen, Lebensdaten, und Geschlecht der Autoren und Autorinnen, Werktitel, eine grobe Zuordnung der Erzählform der Werke (“heterodiegetic”, “homodiegetic”, “autodiegetic”, “epistolary”, “mixed”) usw. angegeben. Damit entspricht die Pflege der Metadaten folgendem FAIR-Prinzip:
Meta(data) are richly described with a plurality of accurate and relevant attributes.
Können die Daten auch dem Prinzip der Interoperabilität entsprechen? Enthalten die Metadaten relevante Referenzen zu weiteren Metadaten und sind sie interoperabel?
2. (Meta)data use vocabularies that follow FAIR principles
3. (Meta)data include qualified references to other (meta)data
Bei der Pflege der Metadaten haben wir uns für das MiMoText Romankorpus dazu entschieden, Normdaten zu den entsprechenden Schriftstellern und Schriftstellerinnen zu recherchieren und zugänglich zu machen. Insbesondere IDs der Normdatensätze Wikidata und VIAF werden für alle erwähnten Autoren und Autorinnen festgehalten, so dass über diese ID weitergehende Informationen abgerufen werden können: Unter der Wikidata-ID Q9068 manifestiert sich beispielsweise der Autor Voltaire. Mithilfe dieser ID lassen sich automatisiert weitere, noch ausführlichere Metadaten abrufen: Wir können über diese ID erfahren, welche maßgeblichen Werke Voltaire verfasst hat (“NOTABLE WORK”), von wem er ideengeschichtlich beeinflusst wurde (“INFLUENCED BY”), in welchen Sprachen er geschrieben hat (“WRITING LANGUAGES”) oder über Schnittstellen zu Wikipedia, Wikiquote und Wikisource seinen Lebenslauf, Zitate und seine Werke im Volltext abrufen.
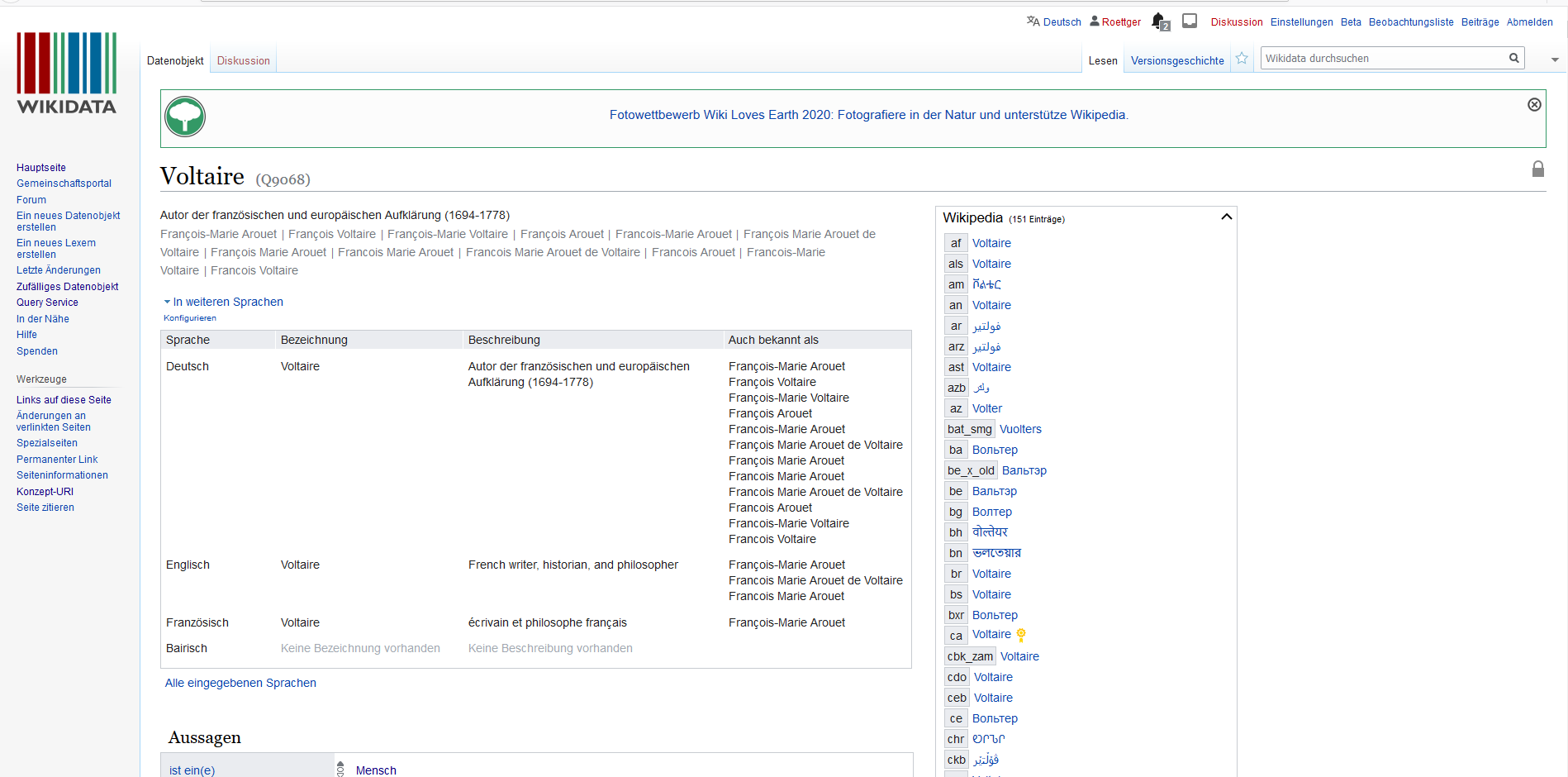
Man kann, wie hier beispielhaft an einer ID erläutert wurde, davon sprechen, dass die angegebenen Metadaten qualifizierte Referenzen auf weitere Metadaten enthalten.
Die erhobenen Daten (französische Romane im Volltext als TEI-konformes XML) stammen aus verschiedenen Quellen: eigene Volltextdigitalisierung, Gallica, Wikisource oder auch die Website Ebooks libres et gratuits. Die Provenienz der Daten ist für jedes Werk und jeden Band in einer Metadatentabelle erfasst und verlinkt. Zusätzlich ist die Information über die Provenienz der Daten in jedem XML-Dokument im teiHeader festgehalten. Es kann somit dem Kriterium R 1.2 “(Meta)data are associated with detailed provenance” der FAIR-Kriterien entsprochen werden.
Bei der Beschreibung von Daten stellt sich zudem immer die Frage, welche Sprache (Programmiersprache, natürliche Sprache) man nutzt, um die Daten auch einer breiten Masse an Wissenschaftlern und Wissenschaftlerinnen zur Nachnutzung und zum Nachvollziehen von Forschungsergebnissen zugänglich zu machen. Wir haben uns für das MiMoText Romankorpus dazu entschieden, mit der Programmiersprache Python zu arbeiten und alle Kommentare im TEI in englischer Sprache zu verzeichnen. TEI selbst als etablierte “lingua franca” und de-facto Standard in der Auszeichnung geisteswissenschaftlicher Daten kann außerdem als “formal, accessible, shared and broadly applicable language for knowledge representation” gewertet werden.
Des weiteren ist die Frage der Langzeitarchivierung ein wichtiger Bestandteil jedes Digitalisierungsvorhabens. Eine Umfrage der AG Digitale Romanistik 2014 untersuchte die Handhabung der Langzeitarchivierung von Forschungsdaten in der Romanistik. Für die Speicherung der eigenen Daten nutzten damals noch fast alle Befragten “die eigene Festplatte oder USB-Stick, rund die Hälfte nutzen kommerzielle Anbieter oder lokale universitäre Speicherdienste, fast niemand nutzt Speicherangebote bei nicht-lokalen Einrichtungen.” Die Problematik des drohenden Datenverlusts und auch der fehlenden Transparenz von Forschungsergebnissen bei fehlender Publikation der Forschungsdaten schien noch nicht Konsens in der romanistischen Forschungscommunity zu sein. Initiativen wie die AG Digitale Romanistik können hier jedoch als Vorreiter angesehen werden. Immer mehr Projekte erkennen den Nutzen von Repositorien und nutzen diese. Nanette Rißler-Pipka unterstreicht zurecht in ihrem Blogpost “Forschungsdaten in Repositorien veröffentlichen” die strukturelle Verschränkung von Forschungsdaten in Repositorien und den FAIR-Prinzipien.
Aktuell werden die MiMoText-Daten in Form von Python Skripten, Primärtexten als TEI/XML und als plain text auf GitHub in einem Repository gespeichert. Die Microsoft-Tochter GitHub stellt eine kollaborative Versionsverwaltung in Form eines netzbasierten Dienstes frei zur Verfügung und wird für eine Vielzahl an Software-Entwicklungsprojekten genutzt. Bereits 2016 berichtete die Zeitschrift Nature über eine zunehmende Bedeutung des Portals in der Wissenschaft. Auch in den Digital Humanities ist die Speicherung von Forschungsdaten auf GitHub mittlerweile gängige Praxis. Doch sind die Daten auf GitHub langfristig gesichert? Das Unternehmen verfolgt eine Strategie der langfristigen Sicherung der Daten in mehreren Stufen:
Hot: Near real-time
Warm: Updated monthly to yearly
Cold: Updated every 5+ years
GitHub-Daten werden bei jedem Zwischenspeichern (“push”) in verschiedenen Datencentern weltweit gespeichert und live über die GitHub API verfügbar gemacht. So kann gesichert werden, dass bei einem technischen Ausfall eines Datenzentrums die Daten an einem weiteren Standort gespeichert bleiben. Das “Github Archive Programme” hat es sich zum ehrgeizigen Ziel gesetzt, im arktischen Eis von Spitzbergen alle aktiven Code-Verzeichnisse für die kommenden 1000 Jahre zu sichern. In regelmäßigen Abständen werden außerdem Kopien des Repositories via Zenodo.org mit einem Digital Object Identifier (DOI) versehen und archiviert.
Neben GitHub und Zenodo diskutieren wir aktuell eine Sicherung der Daten im TextGrid Repository. TextGrid definiert sich selbst als “Langzeitarchiv für geisteswissenschaftliche Forschungsdaten”, das einen “umfangreichen, durchsuchbaren und nachnutzbaren Bestand XML/TEI-kodierter Texte, Bilder und Datenbanken” liefert. TextGrid orientiert sich an den Grundsätzen von Open Access und den FAIR-Prinzipien und wurde 2020 mit dem CoreTrustSeal ausgezeichnet. Bis 2015 wurde TextGrid vom Bundesministerium für Bildung und Forschung (BMBF) gefördert und nach dieser Förderphase in die digitale Forschungsinfrastruktur DARIAH-DE – Virtual Research Infrastructure for the Arts and Humanities migriert. Hier zeigt sich ein entscheidendes Problem der langfristigen Sicherung von Forschungsdateninfrastrukturen: Endet eine finanzielle Förderphase, besteht auch jeweils die Gefahr, dass auch die Dateninfrastruktur nicht mehr gepflegt oder unterhalten wird. Über die Migration in DARIAH konnte diese Klippe für TextGrid vorerst umschifft werden.
Zusammenfassend lässt sich sagen, dass MiMoText, getragen von der Idee von Open Access und Linked Open Data, eine Strategie verfolgt, die die Daten gut auffindbar, frei und offen nachnutzbar, mit relevanten Metadaten versehen an langfristig gesicherten, öffentlich zugänglichen Speicherorten verfügbar macht. Eine Vernetzung mit bereits vorhandenen Ontologien ist über verlinkte Normdaten gegeben. Ein einzigartiges Korpus an sehr bekannten und weniger bekannten französischen Autoren und Autorinnen des 18. Jahrhunderts steht so für die freie Recherche und weitere wissenschaftliche Nutzung bereit.
Jetzt einen Einblick in das GitHub Repository von MiMoText nehmen: https://github.com/MiMoText/roman-dixhuit
Mehr über “Mining and Modeling Text” erfahren unter: https://www.mimotext.uni-trier.de/aktuelles
Bibliographie
- AG Digitale Romanistik: „Ergebnisse der Umfrage der AG Digitale Romanistik zur Langzeitarchivierung von digitalen Forschungsdaten für die Romanistik“, in: Mitteilungsheft des Deutschen Romanistenverbands e.V., Frühjahr 2015, S. 36-40.
- Burnard, Lou. What Is the Text Encoding Initiative? : How to Add Intelligent Markup to Digital Resources. Encyclopédie Numérique. Marseille: OpenEdition Press, 2014. DOI: 10.4000/ books.oep.426
- Deutsche Forschungsgemeinschaft. “12.151 – DFG-Praxisregeln ‘Digitalisierung.’” Accessed June 17, 2020. https://www.dfg.de/formulare/12_151/.
- Erben, Maria; Grüter, Doris; Rohden, Jan: Forschungsdatenmanagement in der Romanistik : Aktuelle Situation und zukünftige Perspektiven. Bonn: Fachinformationsdienst Romanistik, 2018. Online-Ausgabe in bonndoc: http://hdl.handle.net/20.500.11811/1178
- “FID Romanistik: Leitfaden: Archivierung von Forschungsdaten Im DARIAH-DE Repository.” Accessed July 1, 2020. ttps://www.fid-romanistik.de/forschungsdaten/arbeit-mit-forschungsdaten/sichern-und-publizieren-von-forschungsdaten/dariah-de-repository/leitfaden-archivierung-von-forschungsdaten-im-dariah-de-repository/.
- GitHub Archive Program. “GitHub Archive Program.” Accessed June 17, 2020. https://archiveprogram.github.com/.
- GO FAIR. “FAIR Principles.” Accessed May 13, 2020. https://www.go-fair.org/fair-principles/.
- Neuroth, Heike, Andrea Rapp, and Sibylle Söring. “TextGrid: Von der Community – für die Community,” 2015. https://doi.org/10.3249/webdoc-3947.
- Perkel, Jeffrey. “Democratic Databases: Science on GitHub.” Nature 538, no. 7623 (October 2016): 127–28. https://doi.org/10.1038/538127a.
- Rißler-Pipka, Nanette. “Forschungsdaten in Repositorien veröffentlichen.” Romanistik-Blog (blog), June 24, 2020. https://blog.fid-romanistik.de/2020/06/24/forschungsdaten-in-repositorien-veroeffentlichen/.
- Schöch, Christof. “ Big? Smart? Clean? Messy? Data in the Humanities.” Journal of Digital Humanities 02, no. 03 (2013). http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/.
- Wikidata contributors. “Voltaire.” Q9068. Accessed May 20, 2020. https://www.wikidata.org/wiki/Q9068.
- Wilkinson, Mark D., Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, et al. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific Data 3, no. 1 (December 2016): 160018. https://doi.org/10.1038/sdata.2016.18.
Ein Gedanke zu „FAIRe Daten in den Literaturwissenschaften? Das Beispiel „Mining and Modeling Text“ und der französische Roman des 18. Jahrhunderts“