In diesen Tagen wurde der Sammelband mit den Ergebnissen des „IV Congreso Internacional de la Asociación de Humanidades Digitales Hispánicas“ (Info) im Open Access veröffentlicht, der vom 23. -25. Oktober 2019 an der Facultad de Humanidades de Toledo der Universidad de Castilla-La Mancha stattgefunden hatte. Im Abstract des Bandes, der unter dem Oberbegriff „Digitale Geisteswissenschaften als Ausdruck und Untersuchung des digitalen Erbes“ steht, heißt es:
The aim of this contribution is to reflect on the process of building the multilingual European Literary Text Collection (ELTeC) that is being created in the framework of the networking project Distant Reading for European Literary History funded by COST (European Cooperation in Science and Technology). To provide some background, we briefly introduce the basic idea of ELTeC with a focus on the overall goals and intended usage scenarios. We then describe the collection composition principles that we have derived from the usage scenarios. In our discussion of the corpus-building process, we focus on collections of novels from four different literary traditions as components of ELTeC: French, Portuguese, Romanian, and Slovenian, selected from the more than twenty collections that are currently in preparation.
Bei dem im Verlag Hamburg University Press gedruckt und im Open Access veröffentlichten Sammelband «Toward Undogmatic Reading – Narratology, Digital Humanities and Beyond» handelt es sich um eine Festschrift zu Ehren von Jan Christoph Meister, dessen Name eng verbunden ist mit der Verschmelzung der Literaturwissenschaft und den Möglichkeiten einer computergestützten Analyse, lange bevor sich der Begriff Digital Humanities herausgebildet hat. Die Herausgeber*innen Marie Flüh, Dr. Jan Horstmann, Dr. Janina Jacke und Mareike Schumacher führen in der Einführung dazu aus:
Romanistisch Forschende, die überlegen Methoden des Topic Modelling im Rahmen ihrer Forschung anzuwenden, finden in diesem Tutorial der hilfreichen Initiative „The programming historian“ eine gute Einführung. Ulrike Henny-Krahmer hat sich die Mühe gemacht, die bereits existierende Anleitung «Introducción a Topic Modeling y MALLET» von Shawn Graham, Scott Weingart und Ian Milligan gemeinsam mit anderen ins Spanische zu übersetzen und anzupassen: «Introducción a Topic Modeling y MALLET».
Zu welchen Ergebnissen man kommen kann, wenn Methoden der Digital Humanities auf die Untersuchung von Dramen angewandt werden, zeigt eine aktuelle Veröffentlichung in der neuen Ausgabe der Zeitschrift Revista de Humanidades Digitales. Prof. Dr. Hanno Ehrlicher und sein Mitarbeiter Dr. Jörg Lehmann (Romanische Philologie, Univ. Tübingen), sowie Dr. Nils Reiter (Univ. Köln) und Dr. Marcus Willand (Univ. Heidelberg) präsentieren hier eindrucksvoll und nachvollziehbar die Ergebnisse ihrer quantitativen Untersuchung zu Calderón de la Barca.
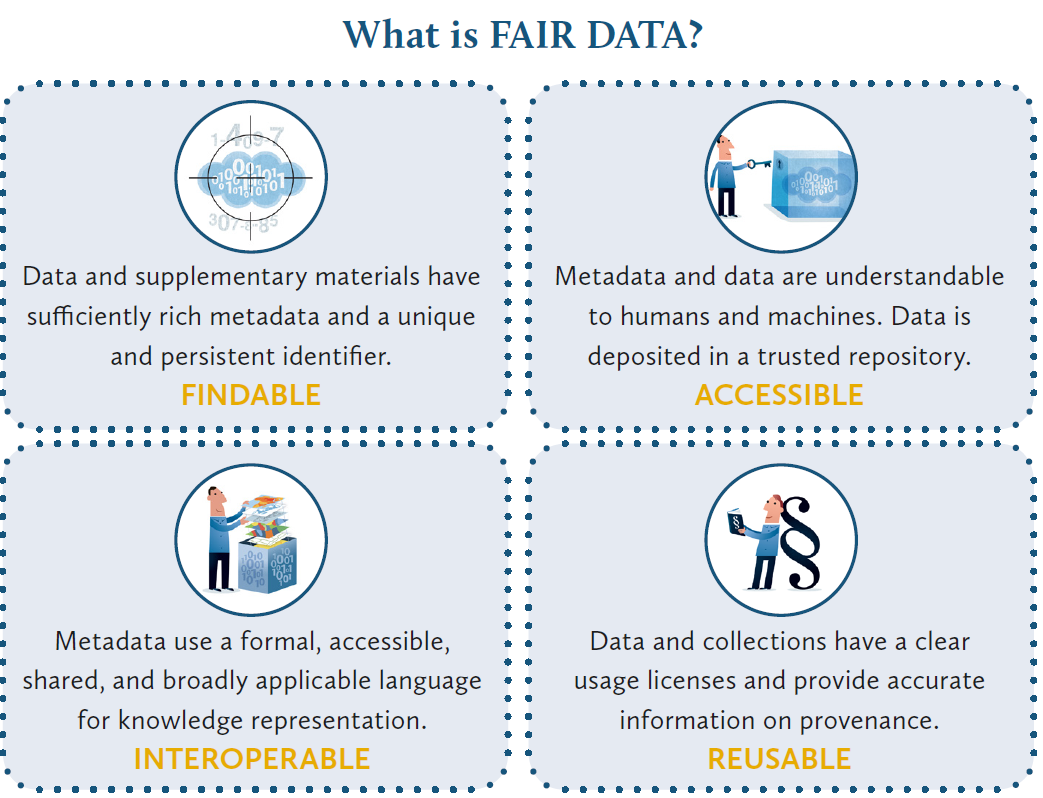
What is FAIR DATA? Quelle: Ligue des Bibliothèques Européennes de Recherche, CC-BY
Gemäß der Fair Data Principles sollen Forschungsdaten “Findable, Accessible, Interoperable, and Re-usable“, also auffindbar, zugänglich, interoperabel und nachnutzbar sein. In der vorliegenden Blogserie zu FAIR-Prinzipien im Kontext romanistischer Projekte wurden bereits die Bedeutung von Repositorien und FAIR data im Kontext der Lexikographie diskutiert.
Im Projekt “Mining and Modeling Text” (2019–2022) des Trier Center for Digital Humanities ist ein Team aus der Computerlinguistik, der Romanistik, der Informatik und der Rechtswissenschaft dabei, ein mehrgliedriges Informationsangebot aufzubauen. Die Informationen speisen sich aus drei Quellen: Primärtexte (französische Romane der Zeit 1750-1800), Sekundärliteratur (relevante literaturhistorische Werke) und relevante bibliographische Daten.
Geleitet von der Idee von Linked Open Data werden die Romane in TEI-konformes XML gewandelt und mit Normdaten wie Wikidata verknüpft. Die Vision des Forschungsprojekts ist es, literaturhistorisch relevante Informationen maschinell zu extrahieren und so in Form von einfachen Aussagen zu modellieren, dass sie im Sinne des Semantic Web abfragbar (via SPARQL) zur Verfügung stehen.
Doch sind die bisher erhobenen Forschungsdaten den FAIR-Prinzipien entsprechend gut zugänglich, umfänglich erläutert, mit entsprechenden Lizenzen versehen und stehen sie nachnutzbar aufbereitet für die Forschungscommunity zur Verfügung?
Mit ihrem im Open Access veröffentlichten Artikel „Humanidades Digitales y Literatura española: 50 años de repaso histórico y panorámica de proyectos representativos“ gibt Laura Hernández Lorenzo (Universidad Nacional de Educación a Distancia, España) einen wertvollen Überblick über die vergangenen 50 Jahre auf dem Feld der Digital Humanities zur spanischen Literatur. Die Auflistung wichtiger Projekte und die umfangreiche Bibliographie sind eine wichtige Orientierung für alle, die sich hier einen raschen Überblick verschaffen wollen.
Ganz im Zeichen der Digital Humanities steht der mittlerweile 11. Workshop des Toletum-Netzwerks zur Erforschung der Iberischen Halbinsel in der Antike. Vom 22. bis 24. Oktober 2020 werden im Hamburger Warburg-Haus und online die Bedeutung und Anwendung digitaler Methoden in den beteiligten Disziplinen behandelt:
 In diesen Tagen wurde der Sammelband mit den Ergebnissen des „IV Congreso Internacional de la Asociación de Humanidades Digitales Hispánicas“ (Info) im Open Access veröffentlicht, der vom 23. -25. Oktober 2019 an der Facultad de Humanidades de Toledo der Universidad de Castilla-La Mancha stattgefunden hatte. Im Abstract des Bandes, der unter dem Oberbegriff „Digitale Geisteswissenschaften als Ausdruck und Untersuchung des digitalen Erbes“ steht, heißt es:
In diesen Tagen wurde der Sammelband mit den Ergebnissen des „IV Congreso Internacional de la Asociación de Humanidades Digitales Hispánicas“ (Info) im Open Access veröffentlicht, der vom 23. -25. Oktober 2019 an der Facultad de Humanidades de Toledo der Universidad de Castilla-La Mancha stattgefunden hatte. Im Abstract des Bandes, der unter dem Oberbegriff „Digitale Geisteswissenschaften als Ausdruck und Untersuchung des digitalen Erbes“ steht, heißt es:




")