Seit April erscheint Fabulari – ein wissenschaftlicher Podcast über Literatur und Film in der Romania – zuverlässig alle 14 Tage. Die Herausgeber:innen Teresa Hiergeist, Benjamin Loy und Stefanie Mayer widmen sich darin den aktuellen Forschungsfragen der Literatur-, Medien- und Kulturwissenschaften.
La web es un canal que transmite flujos de información en forma de red conectando nodos, desafiando la geografía y haciendo las distancias inexistentes. Es también fluidez, proceso, falta de contexto y superabundancia. Los principios FAIR pretenden corregir esta situación para que los datos científicos no se pierdan en el maremágnum de información, sino que sean fáciles de encontrar, accesibles, interoperables y reutilizables. Parece como si las organizaciones (pienso en FORCE11, ALLEA o LIBER) que han alentado la diseminación de los principios FAIR trabajasen a contrapelo, luchando contra algunos de los rasgos más característicos del medio digital y promoviendo una cultura científica más abierta y colaborativa.
Es por ello que en los últimos tiempos me pregunto si hay algo más que retórica en los principios FAIR. ¿Son “realizables” en la práctica? EnFAIR enough? Building Digital Humanities Resources in an Unequal World, intenté responder a estas preguntas teniendo en cuenta proyectos de cooperación Norte-Sur y llegué a una conclusión escéptica y muy pragmática. Los principios FAIR gustan a todo el mundo: sugieren una idea de justicia y equidad que nos interpela a todos y por eso como estrategia de branding son perfectos; pero no son fáciles de llevar a cabo, sobre todo en contextos en que la infraestructura tecnológica es deficiente, escasa o poco robusta. Por eso no debemos dejarnos cegar por sus destellos sino interrogarlos de forma crítica. „Contra la retórica FAIR“ weiterlesen
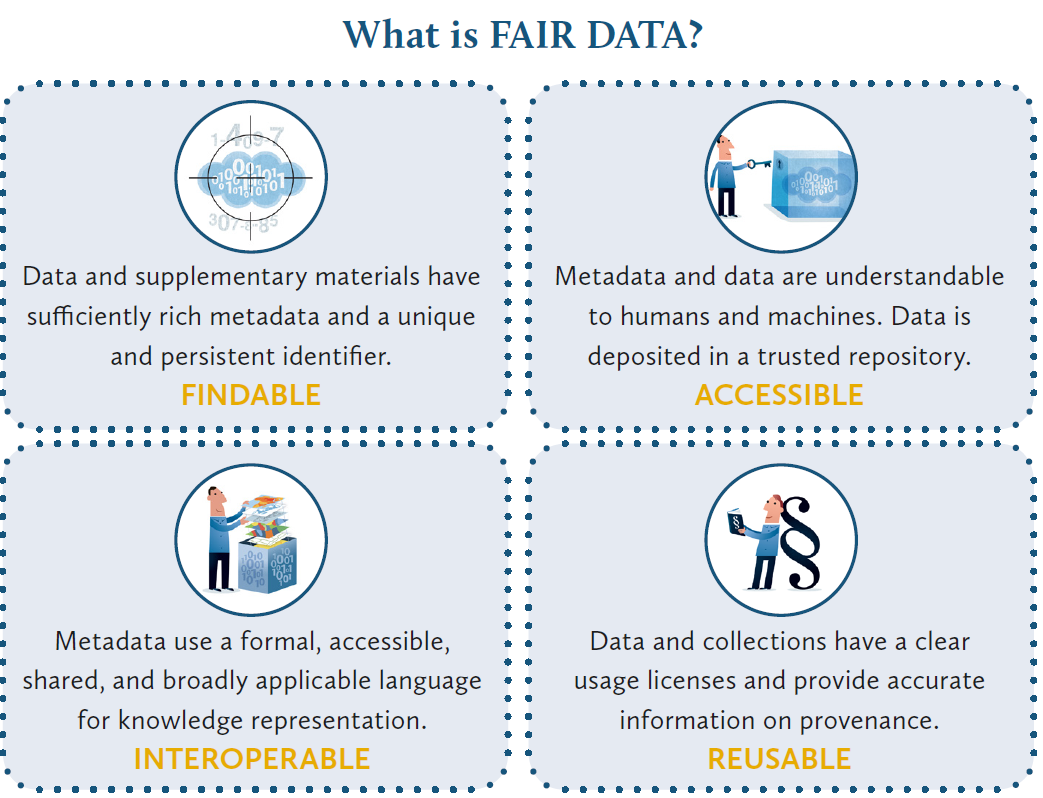
What is FAIR DATA? Quelle: Ligue des Bibliothèques Européennes de Recherche, CC-BY
Gemäß der Fair Data Principles sollen Forschungsdaten “Findable, Accessible, Interoperable, and Re-usable“, also auffindbar, zugänglich, interoperabel und nachnutzbar sein. In der vorliegenden Blogserie zu FAIR-Prinzipien im Kontext romanistischer Projekte wurden bereits die Bedeutung von Repositorien und FAIR data im Kontext der Lexikographie diskutiert.
Im Projekt “Mining and Modeling Text” (2019–2022) des Trier Center for Digital Humanities ist ein Team aus der Computerlinguistik, der Romanistik, der Informatik und der Rechtswissenschaft dabei, ein mehrgliedriges Informationsangebot aufzubauen. Die Informationen speisen sich aus drei Quellen: Primärtexte (französische Romane der Zeit 1750-1800), Sekundärliteratur (relevante literaturhistorische Werke) und relevante bibliographische Daten.
Geleitet von der Idee von Linked Open Data werden die Romane in TEI-konformes XML gewandelt und mit Normdaten wie Wikidata verknüpft. Die Vision des Forschungsprojekts ist es, literaturhistorisch relevante Informationen maschinell zu extrahieren und so in Form von einfachen Aussagen zu modellieren, dass sie im Sinne des Semantic Web abfragbar (via SPARQL) zur Verfügung stehen.
Doch sind die bisher erhobenen Forschungsdaten den FAIR-Prinzipien entsprechend gut zugänglich, umfänglich erläutert, mit entsprechenden Lizenzen versehen und stehen sie nachnutzbar aufbereitet für die Forschungscommunity zur Verfügung?
„Repositorium“ ist zunächst ein eher technischer Begriff aus dem Bereich der Forschungsdateninfrastruktur, der zur Beschreibung der nachhaltigen Verwaltung und Speicherung von Daten verwendet wird. Was Forschungsdaten sein können und warum wir diese langfristig und nachhaltig sichern sollten, dazu hat die AG Digitale Romanistik bereits 2014 mit einer Umfrage zu diesem Thema und 2017 mit einem Positionspapier zu „Open Access und Forschungsdaten in der Romanistik“ informiert. Außerdem hat der FID Romanistik 2018 ein Papier zum „Forschungsdatenmanagement in der Romanistik“ veröffentlicht, das von der AG Digitale Romanistik unterstützt wird. Seitdem sind die Möglichkeiten zur Veröffentlichung von Forschungsdaten schneller gewachsen als die Anzahl der in der Romanistik neu entstandenen und publizierten Forschungsdaten selbst – so zumindest der Eindruck, wenn man in die bisher via romanistik.de gemeldeten Ressourcen schaut. Kürzliche Bemühungen der CLiGS-Forschergruppe (mit der Veröffentlichung einer text-box und der COST Action Distant Reading deuten aber eine Veränderung des Trends an. Dagegen zeigt das Verzeichnis romanistischer Forschungsdaten des FID Romanistik allein zu den Internet-Ressourcen eine fast unüberschaubare Vielfalt, die wiederum zusätzliche Katalogisierung oder Verschlagwortung erfordert, wie hier am Beispiel der Sortierung nach Sprachraum, etc. ersichtlich.
 Seit April erscheint Fabulari – ein wissenschaftlicher Podcast über Literatur und Film in der Romania – zuverlässig alle 14 Tage. Die Herausgeber:innen Teresa Hiergeist, Benjamin Loy und Stefanie Mayer widmen sich darin den aktuellen Forschungsfragen der Literatur-, Medien- und Kulturwissenschaften.
Seit April erscheint Fabulari – ein wissenschaftlicher Podcast über Literatur und Film in der Romania – zuverlässig alle 14 Tage. Die Herausgeber:innen Teresa Hiergeist, Benjamin Loy und Stefanie Mayer widmen sich darin den aktuellen Forschungsfragen der Literatur-, Medien- und Kulturwissenschaften.