Julia Röttgermann und Christof Schöch
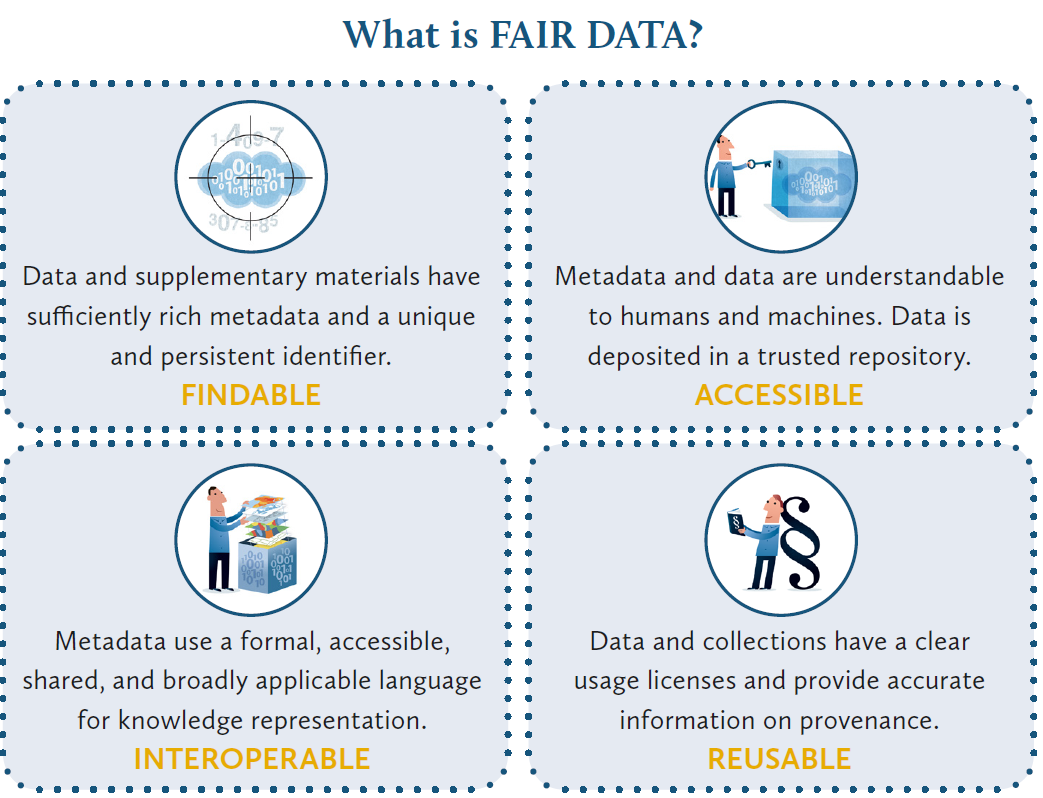
Gemäß der Fair Data Principles sollen Forschungsdaten “Findable, Accessible, Interoperable, and Re-usable“, also auffindbar, zugänglich, interoperabel und nachnutzbar sein. In der vorliegenden Blogserie zu FAIR-Prinzipien im Kontext romanistischer Projekte wurden bereits die Bedeutung von Repositorien und FAIR data im Kontext der Lexikographie diskutiert.
Im Projekt “Mining and Modeling Text” (2019–2022) des Trier Center for Digital Humanities ist ein Team aus der Computerlinguistik, der Romanistik, der Informatik und der Rechtswissenschaft dabei, ein mehrgliedriges Informationsangebot aufzubauen. Die Informationen speisen sich aus drei Quellen: Primärtexte (französische Romane der Zeit 1750-1800), Sekundärliteratur (relevante literaturhistorische Werke) und relevante bibliographische Daten.
Geleitet von der Idee von Linked Open Data werden die Romane in TEI-konformes XML gewandelt und mit Normdaten wie Wikidata verknüpft. Die Vision des Forschungsprojekts ist es, literaturhistorisch relevante Informationen maschinell zu extrahieren und so in Form von einfachen Aussagen zu modellieren, dass sie im Sinne des Semantic Web abfragbar (via SPARQL) zur Verfügung stehen.
Doch sind die bisher erhobenen Forschungsdaten den FAIR-Prinzipien entsprechend gut zugänglich, umfänglich erläutert, mit entsprechenden Lizenzen versehen und stehen sie nachnutzbar aufbereitet für die Forschungscommunity zur Verfügung?


