
Forschungsdaten ist einer dieser Begriffe, der für manche Forschende in den Textwissenschaften vielleicht noch ein Füllwort im akademischen Diskurs darstellt, zu dem sie keine Beziehung haben (wollen), weil es so nach MINT-Fach schmeckt. Dabei reicht schon eine kleine Justierung der persönlichen Definition des Begriffs, und schon watet man knietief durch Forschungsdaten, ohne am eigenen Forschungsverhalten irgendetwas verändert zu haben. Wenn man erst einmal weiß, wonach man sucht, kann man im Handumdrehen ganze Datenbanken füllen.
Es ist ein ausdrückliches Anliegen des FID Romanistik, das Bewusstsein dafür zu schärfen, dass auch in der Romanistik durchaus Forschungsdaten entstehen, welche das sind und wie man sie aufstöbern und für die eigene Forschung nutzen kann.  Die andere, nicht weniger wichtige Seite derselben Medaille ist die Frage, wie man als Forschende*r die eigenen Forschungsdaten so aufbereiten und veröffentlichen kann, dass Kolleginnen und Kollegen vom eigenen Fach und aus benachbarten Disziplinen sie ihrerseits verwenden und in bewährter akademischer Manier zitierend darauf verweisen können, sei es in wissenschaftlichen Publikationen oder in der Dokumentation ihrer eigenen Forschungsdaten. Auch in dieser Hinsicht steht der FID Romanistik mit Rat und Tat und den Informationen auf seinem Internet-Portal geneigten Forschenden zur Seite.
Die andere, nicht weniger wichtige Seite derselben Medaille ist die Frage, wie man als Forschende*r die eigenen Forschungsdaten so aufbereiten und veröffentlichen kann, dass Kolleginnen und Kollegen vom eigenen Fach und aus benachbarten Disziplinen sie ihrerseits verwenden und in bewährter akademischer Manier zitierend darauf verweisen können, sei es in wissenschaftlichen Publikationen oder in der Dokumentation ihrer eigenen Forschungsdaten. Auch in dieser Hinsicht steht der FID Romanistik mit Rat und Tat und den Informationen auf seinem Internet-Portal geneigten Forschenden zur Seite.
Neben einführenden Informationen und Verweisen auf Vertiefungsangebote stellt der romanistische FID auch eine Datenbank zur Verfügung, in der relevante Forschungsdatensätze zusammengetragen, beschrieben und gebündelt auffindbar gemacht werden. Die Mitarbeiter*innen des FID begeben sich hierfür teilweise auf eigene Faust auf die Suche in Publikationen, auf Projekt-Websites oder in diversen Repositorien. Auf einige der Einträge wurden wir aber zum Beispiel auch über das Meldeformular für Ressourcen auf romanistik.de aufmerksam, das eine gute Möglichkeit bietet, eigene Korpora oder für andere Romanist*innen interessante Daten-Anhänge zu einer Publikation in der Fachgemeinschaft bekannt zu machen.
In der letzten Zeit haben die Früchte unserer Sammelwut eine vielleicht nicht historische, womöglich aber doch nennenswerte Marke geknackt: Die Datensätze sind vierstellig geworden – 1001 Einträge zu Forschungsdaten hat die Datenbank inzwischen zu bieten.
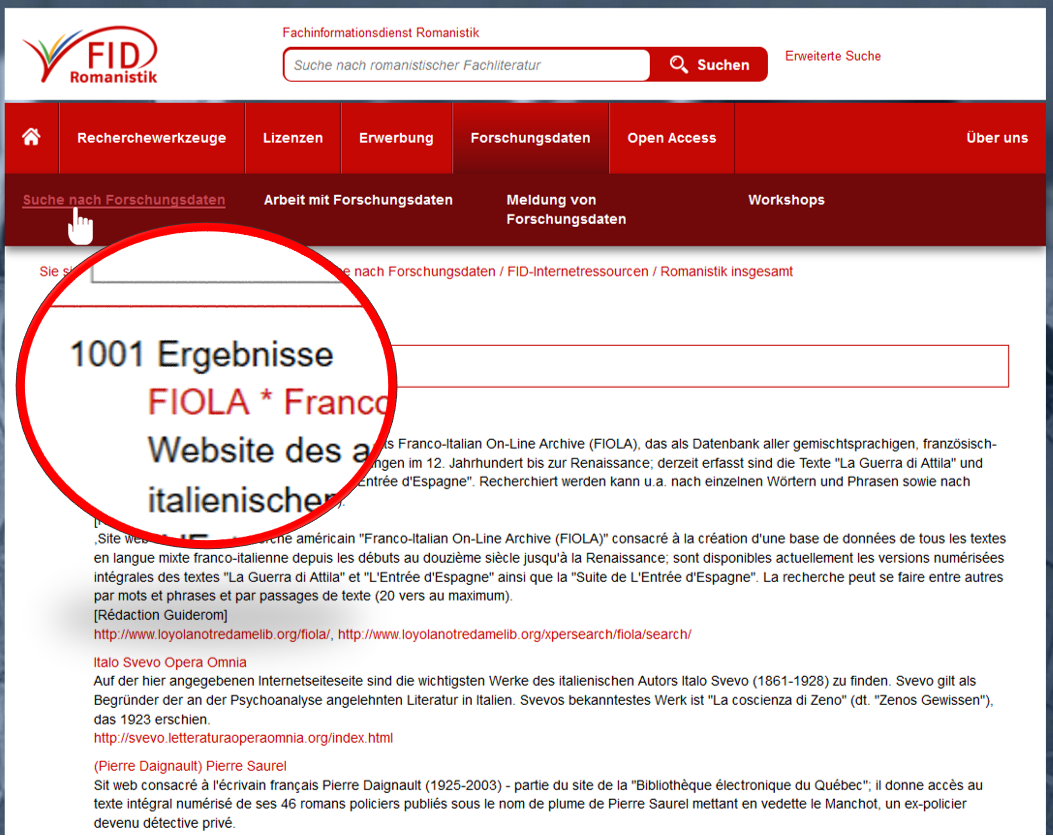
Dazu gehören Textsammlungen, Tools, linguistische Korpora, virtuelle Bibliotheken, Wörterbücher, digitalisierte Handschriften, aber auch Forschungsumgebungen, in denen diverse Datentypen kombiniert werden, um beispielsweise anhand innovativer Visualisierungsmöglichkeiten Fragen zu beantworten, die man sich noch gar nicht gestellt hatte – wenn eine kleine Übertreibung gestattet ist.
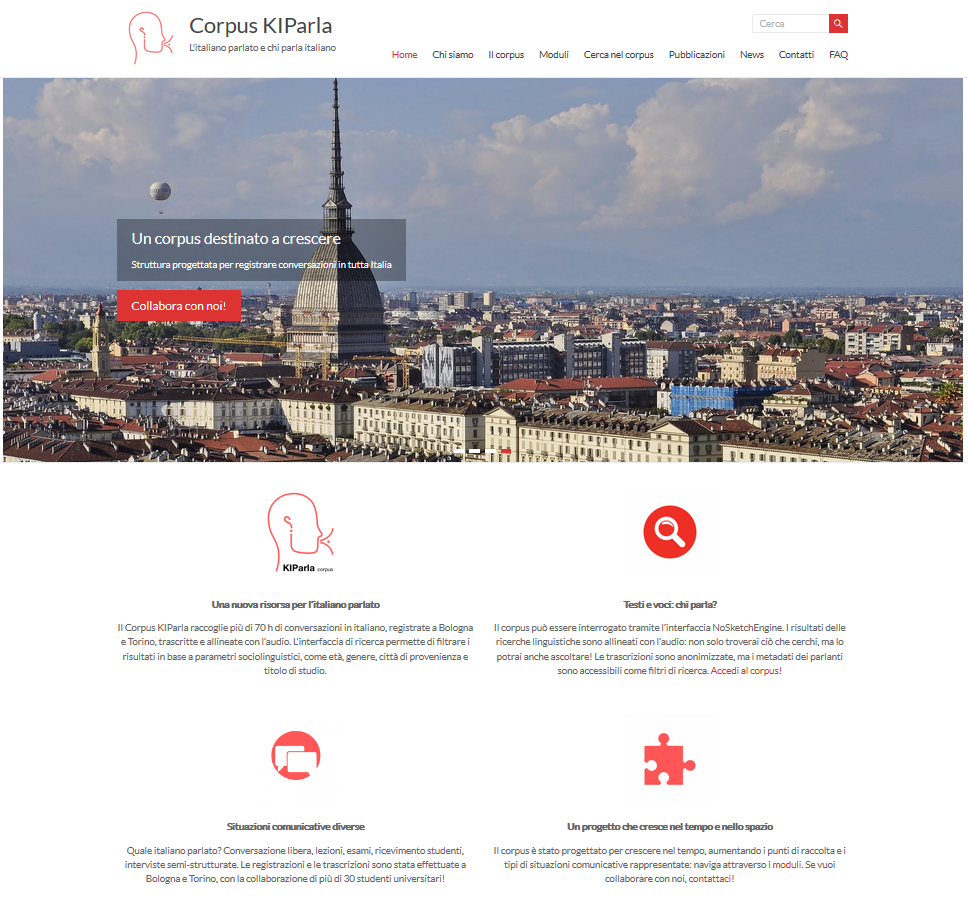
Ein paar Einträge haben gemeinsam den Zähler über die 1000er-Schwelle gehievt. Da wäre einmal das Corpus KIParla – L’italiano parlato e chi parla italiano (https://kiparla.it). Transkribiertes Audiomaterial von derzeit rund 70 Stunden Länge gewährt Einblick in das gesprochene Italienisch in Bologna und Turin. Sprecher*innen unterschiedlicher geographischer und sozialer Herkunft wurden in unterschiedlichen Situationen aufgezeichnet, etwa um den regionalsprachlichen Einschlag des Italienischen zu untersuchen. Für ausgefeilte Suchanfragen nutzt das Projekt die Software NoSketchEngine, aus deren Trefferliste direkt auf die betreffende Stelle in den ebenfalls zur Verfügung gestellten Audiodateien zugegriffen werden kann.
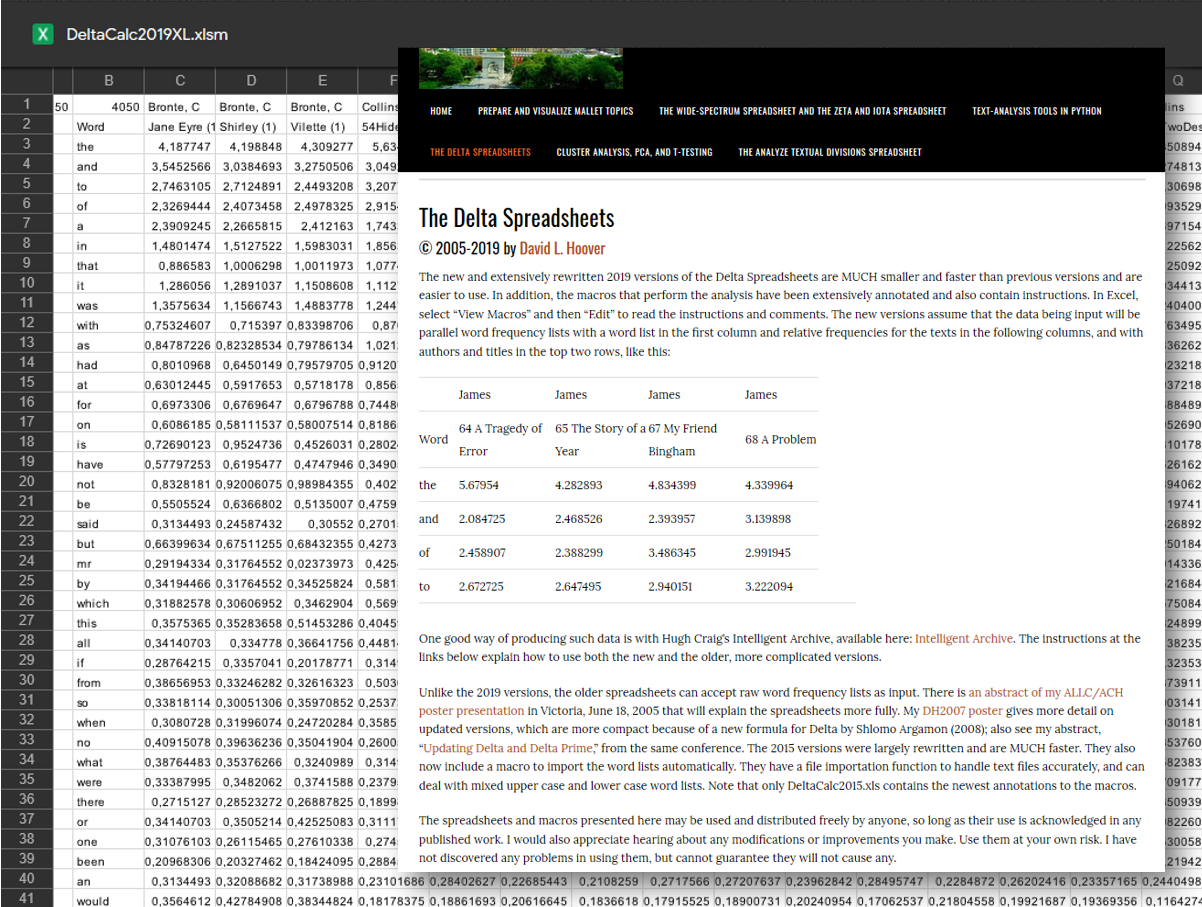
Ebenfalls neu aufgenommen wurden die schon etwas älteren, 2019 jedoch aktualisierten Spreadsheets von David L. Hoover, die es ermöglichen, stilometrische Untersuchungen unter anderem anhand des Delta- bzw. anhand des Zeta- oder Iota-Distanzmaßes von John Burrows vorzunehmen. Die mit den entsprechenden Makros aufbereiteten Tabellen (im *.xlsm-Format) müssen nur mit Wortfrequenzlisten gefüttert werden, um die gewünschten statistischen Zahlenwerte zu erhalten, und schon hat man fein säuberlich geclusterte Textgrüppchen vorliegen und kann herausknobeln, wer sich wahrscheinlich hinter dem neuesten Pseudonym verbirgt. Natürlich ist es etwas komplizierter als das, aber Hoover liefert ausführliche Informationen, wie man die Parameter der Analyse an die Komplexität der eigenen Fragestellung anpassen kann (und für die Generierung der Wortfrequenzlisten empfiehlt er beispielsweise Hugh Craigs Programm Intelligent Archive ).
Das französische „Deep-Sequoia“-Korpus wurde im Mai 2019 in seiner Version 9.0 veröffentlicht und hält, wie der Name schon sagt, neben den geläufigen Annotationen grammatischer Dependenz auch sogenannte „deep syntactic annotations“ bereit, um den Verquickungen der Syntax auf die Spur zu kommen. Mehr als 3000 entsprechend von Hand markierte Sätze sind in diesem Korpus enthalten. Als Quellen haben unter anderem das Europarl-Korpus, die Zeitung L’Est Republicain und die französische Wikipedia hergehalten. In der neuesten Fassung sind auch die semantischen und grammatischen Mehrwortausdrücke sowie eindeutig benennbare Einheiten erfasst und ausgezeichnet worden.
Schließlich wurden mit dem Datensatz „La Segunda Celestina“ die begleitenden Forschungsdaten zu einer Veröffentlichung aus dem Bereich der Stilometrie aufgenommen. Laura Hernández Lorenzo und Joanna Byszuk haben für ihre Untersuchung „Challenging Stylometry: The Authorship of the Baroque Play La Segunda Celestina“, die 2019 auf der Digital Humanities Conference in Utrecht vorgestellt wurde, ein interessantes Textkorpus zusammengetragen. Es enthält einerseits eine Reihe Stücke aus dem Canon-60 von J. Oleza Simó, andererseits aber auch einige für die eigene Analyse wertvolle Texte, die in keiner brauchbaren digitalisierten Volltext-Version vorlagen und sich nicht zufriedenstellend mithilfe optischer Zeichenerkennung (OCR) aus bestehenden Digitalisaten erfassen ließen, weshalb sie kurzerhand von den Autorinnen manuell transkribiert werden mussten. Das resultierende „Corpus of Golden Age Spanish Plays“ wurde – ergänzend zur Veröffentlichung des Artikels (siehe Literaturhinweise) – mitsamt einer Liste der enthaltenen Stücke, der Vortragsfolien und einem kurzen Bericht über die Schwierigkeiten bei der optischen Zeichenerkennung auf Github veröffentlicht.
Natürlich ist die glatte Zahl von 1000 Datenbankeinträgen höchstens ein Etappenziel gewesen, und schon mit dem nächsten zu erfassenden Datensatz erhebt sich am zugegeben ambitionierten Horizont der nächste Gipfel der 2000.
Tragen Sie dazu bei, den Weg dorthin so spannend wie möglich zu gestalten, und informieren Sie uns über weitere Forschungsdatensätze, die aus romanistischer Perspektive interessant, kurios, inspirierend oder bahnbrechend erscheinen – oder schlicht in unserer Datenbank bisher fehlen. Sie können dafür das bereits erwähnte Meldeformular auf romanistik.de nutzen oder ganz einfach eine E-Mail an den FID Romanistik senden.

Literaturhinweise zu den im Text erwähnten Projekten:
- KIParla – L’italiano parlato e chi parla italiano (https://kiparla.it).
- Dazu: Caterina Mauri, Silvia Ballarè, Eugenio Goria, Massimo Cerruti e Francesco Suriano (forth.), „KIParla corpus: a new resource for spoken Italian“. In: Proceedings of the 6th Italian conference on Computational Linguistics CLiC-it (http://ceur-ws.org/Vol-2481/paper45.pdf).
- David L. Hoover, The Delta Spreadsheets (https://wp.nyu.edu/exceltextanalysis/deltaspreadsheets/), 2005–2019.
- Intelligent Archive: Hugh Craig. Rosella, Intelligent Archive 3.0 beta. 2018. Centre for 21st Century Humanities, University of Newcastle, Australia. (https://c21ch.newcastle.edu.au/ia/)
- Deep-sequoia – A French corpus with surface and deep syntactic annotations. V. 9.0. (Mai 2019) (https://deep-sequoia.inria.fr/)
- Dazu: Marie Candito, Guy Perrier, Bruno Guillaume, Corentin Ribeyre, Karën Fort, Djamé Seddah and Éric de la Clergerie. (2014) Deep Syntax Annotation of the Sequoia French Treebank. Proc. of LREC 2014, Reykjavic, Iceland. (https://hal.inria.fr/hal-00969191)
- Materialien zu „La Segunda Celestina“. https://github.com/JoannaBy/La-Segunda-Celestina
- Vortrag: Laura Hernández Lorenzo / Joanna Byszuk. „Challenging Stylometry: The Authorship of the Baroque Play La Segunda Celestina“, DH2019, 9.–12. Juli 2019, Utrecht. (https://dev.clariah.nl/files/dh2019/boa/0576.html)
- Canon-60: Joan Oleza Simó (coordinador). Canon 60. La colección esencial del TC/12. Teatro clásico español (http://www.cervantesvirtual.com/partes/682072/canon-60-la-coleccion-esencial-del-tc12-teatro-clasico-espanol | https://tc12.uv.es/?page_id=3626)